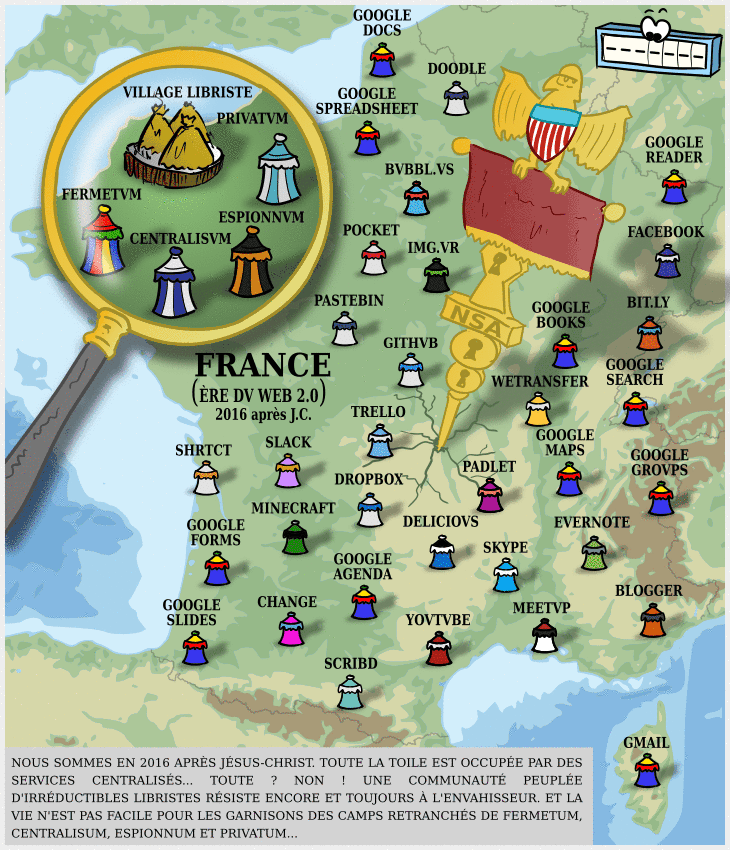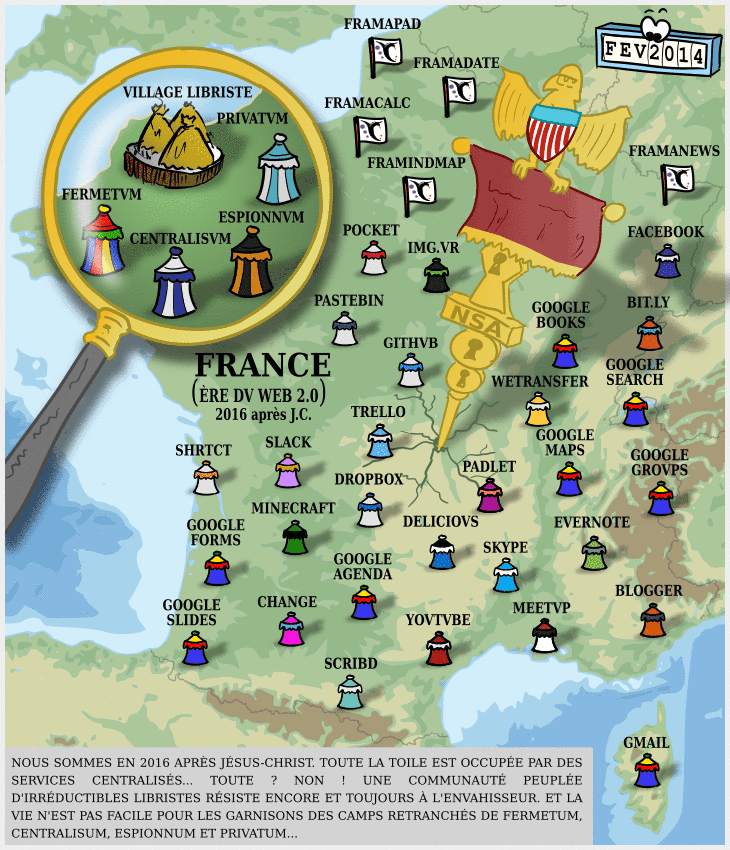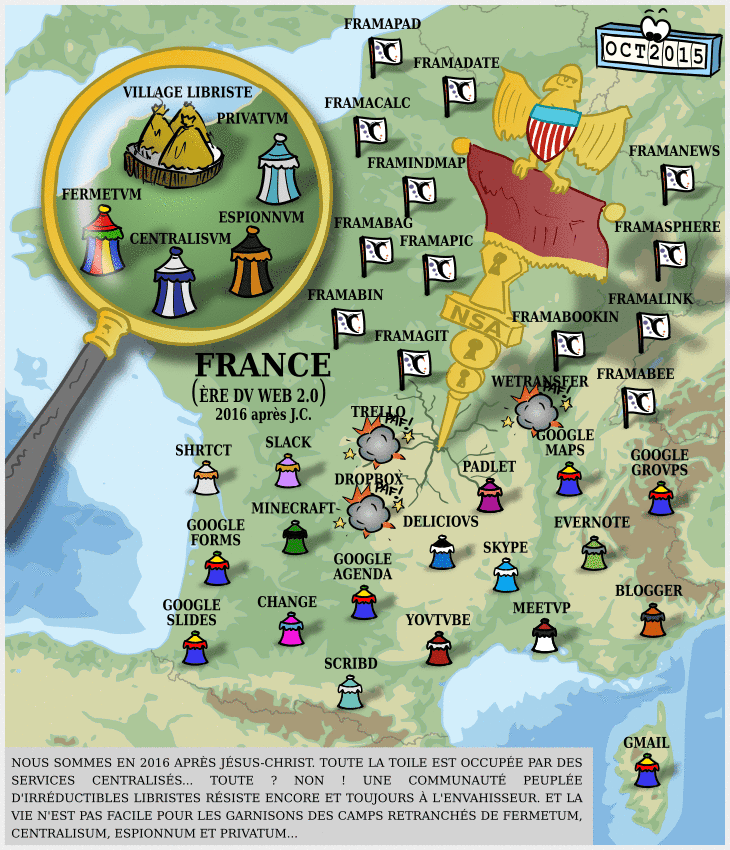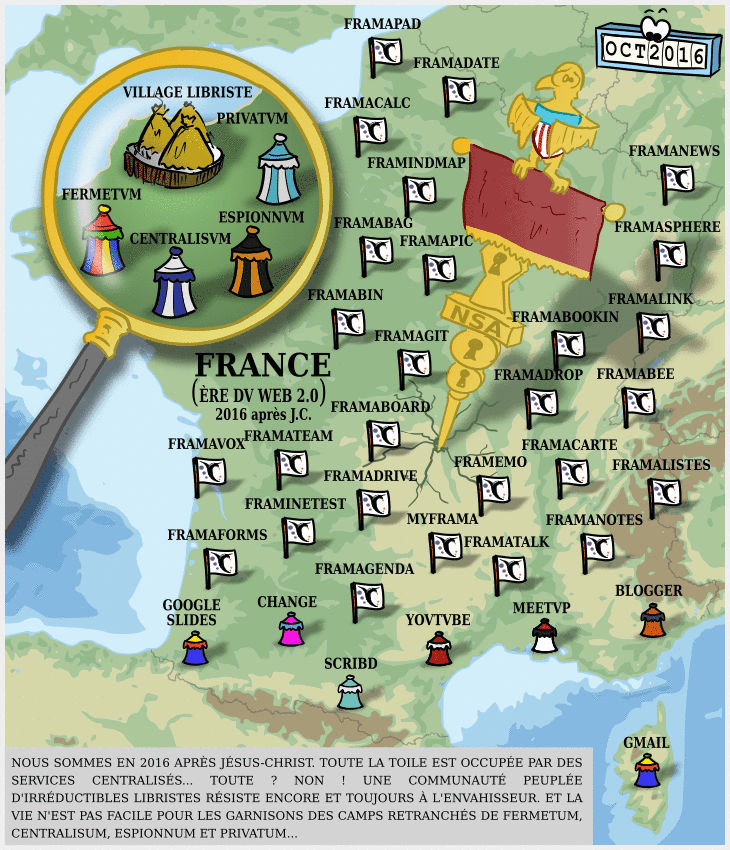
Facebook : prendre un peu de recul et de hauteur
Comprendre Facebook (3/3) : L’internet des API, le web des applications
Par Hubert GUILLAUD – Licence CC by-nc
Pour les 500 millions d’utilisateurs de Facebook il semble n’y avoir qu’une manière d’accéder à Facebook : celle de se connecter sur le réseau social pour consulter son mur d’activité (le “NewsFeedâ€). Pourtant, via Facebook Connect, on a déjà vu qu’il y en avait une autre, distante, permettant d’interagir avec les services de Facebook depuis d’autres sites. Il y en a encore une autre, réservée aux services informatiques des sites qui utilisent Facebook. Cet autre accès passe par les API, les interfaces de programmation, c’est-à -dire des jeux de données ouverts qui permettent aux développeurs d’utiliser les services proposés par Facebook et qui sont l’une des clefs du fonctionnement du web 2.0.
Car derrière tous les systèmes fermés que d’aucun dénoncent à grands cris, il y a avant tout des systèmes informatiques qui discutent entre eux, il y a des systèmes “ouverts†(souvent gratuits plus que payants, sauf si on dépasse un certain niveau ou volume d’utilisation des données accessibles). “Ouverts†à tout le moins aux systèmes techniques, plutôt qu’aux seuls utilisateurs. Si le web semble se refermer, par la mise en place d’écosystèmes propres comme le constatait Chris Anderson dans Le web est mort, vive l’internet, il faut néanmoins reconnaître que ces écosystèmes savent discuter entre eux. Mieux, pour atteindre la masse critique d’utilisateurs, il est bien souvent impossible que cette discussion n’ait pas lieu.
C’est bien en tout cas dans les interfaces de programmation que se concoctent le web d’aujourd’hui et le web de demain : dans les négociations permettant d’accéder aux services des uns et des autres, dans les mashups de services où la bonne alchimie créera le bon service. De nombreuses start-ups naissent de ces croisements (et des matrices permettent d’ailleurs d’imaginer leurs croisements). Les interfaces de programmations ne sont pas des technologies cachées : la plupart des sites qui en proposent documentent ouvertement les conditions d’accès, précisent clairement les conditions d’utilisation. Mais ce sont des technologies relationnelles discrètes, des répertoires de données qui échangent des droits d’accès, des utilisations, que le public ne voit pas. Ce sont elles qui permettent le plus souvent le développement d’applications web ou logicielles, c’est-à -dire de micrologiciels que les échanges de données rendent fonctionnels.
Qu’est-ce qu’une interface de programmation ?
Il existe deux façons de donner accès à des données sur le web, explique Charles Nepote responsable du programme Données publiques de la Fing. Tout d’abord un accès direct à un fichier contenant les données. C’est souvent la méthode la plus simple, car les outils de gestion proposent généralement une fonction d’export des données sous forme de fichier. Elle est cependant moins bien adaptée lorsque les données changent souvent et qu’il y en a beaucoup : cela oblige les réutilisateurs à recharger fréquemment l’ensemble du fichier et peut être consommateur en ressources système et réseau.
C’est pourquoi se développent fréquemment un mode d’accès direct aux données uniquement nécessaires à travers une interface de programmation (API).
Pour Karl Dubost, chargé des relations avec les développeurs chez Opera, l’API n’est rien d’autre qu’“un protocole de communication pour accéder à un serviceâ€. “De la même façon qu’avec un logiciel de base de données, on a un vocabulaire pour accéder aux données et faire une requête, l’API permet de construire des interrogations via une interface normaliséeâ€. Les fonctionnalités proposées par les API évoluent selon les services et au cours du temps. Par exemple, Facebook propose plusieurs API : celle pour s’authentifier, celle pour explorer et exploiter le graphe social des utilisateurs, etc.
Une API va permettre à un programme de demander à l’application qui fournit les données, uniquement celles dont elle a besoin ou auxquelles il souhaite ou peu accéder. Les grands acteurs du numérique en général et du web particulier, comme Google, Amazon, Facebook, Twitter, … ont établi leur succès grâce à leurs APIs. Une API est donc un protocole d’accès à un système d’information pour un autre système d’information, afin qu’ils échangent des données entre eux. Ce à quoi ils ont accès et les conditions de cet accès sont clairement décrits et documentés par l’interface, selon les jeux de données qui peuvent s’échanger. Via des API, on peut construire un système de réservation de billets de trains ou d’avion (en utilisant les API proposées par les transporteurs), utiliser des banques d’images (comme celles des agences de presse) ou utiliser des services spécifiques (faire correspondre cette banque d’image à un service de reconnaissance d’image lui-même accessible via une API).

Image : la croissance du nombre d’API disponibles et de leur utilisation par Programmable Web.
Les API sont des interfaces d’accès aux données numériques, comme l’explique Christian Fauré. C’est une porte d’entrée qui permet de contrôler l’exposition et l’utilisation des données numériques produites par un service. C’est un service logistique qui s’adresse aux autres services et aux développeurs pour faciliter l’échange d’informations. Chaque API à ses particularités : ses clefs d’accès, le nombre de requêtes maximales par clefs d’accès, les données accessibles (et celles qui ne le sont pas), les fonctions de manipulation des données (celles qui sont proposées en lecture seule comme celles qui pourront être écrites par un service tiers permettant par exemple à un service d’écrire à votre place sur votre mur Facebook quand vous l’utilisez et si vous l’avez autorisé). Elles permettent donc à des services de communiquer entre eux, de croiser leurs données, d’utiliser les données des uns et des autres, de manière plus ou moins transparente pour l’utilisateur.
API : de quoi l’utilisateur est-il maître ?
Plus ou moins transparente. Dans Facebook par exemple, quand vous installez une application, celle-ci vous demande en langage (plus ou moins) clair si vous souhaitez que les données que cette application va mémoriser échangent avec Facebook. Elle se résume souvent par une page d’autorisation qui n’est pas sans poser problème, comme s’en plaint Danny Sullivan, puisque la plupart du temps, nous n’avons pas d’autres choix que d’accepter ou refuser la communication, quand bien même bien des données récupérées sembleraient inutiles à son fonctionnement. Nous n’avons aucune capacité d’ajustement des données récupérées. Les applications demandent souvent bien plus d’information qu’elles n’en ont besoin et l’utilisateur n’a rarement d’autre choix que d’approuver ce vol ou de ne pas utiliser l’application en question.

Image : exemple d’une demande d’autorisation d’une application dans Facebook listant tout ce à quoi elle demande accès sans que nous puissions moduler quoi que ce soit.
Bien souvent, les règles qui régissent les interfaces de programmation ne sont pas les mêmes que celles que connaissent les utilisateurs passant par le service principal. Sur Twitter.com par exemple, il est difficile de trouver un tweet particulier ou de remonter loin dans le temps… Le moteur de Twitter ne semble pas avoir une longue mémoire de nos Tweets. Mais ce n’est pas le cas des API utilisées par des services tiers, comme le moteur de recherche SnapBird.
Sur Facebook, les choses qu’on apprécie (like) disparaissent peu à peu de nos murs (et de nos mémoires), mais ce n’est pas le cas des interfaces de programmation de Facebook qui elles savent très bien que vous avez apprécier tel groupe ou telle marque il y a plusieurs mois de cela, et l’utiliser pour vous proposer des recommandations ou des publicités adaptées à votre profil.
Il y a une dissymétrie pour l’usager entre ce à quoi accèdent les services qui se branchent sur les API et ce à quoi accède l’usager, limité à la seule pratique du site web dudit service. Tant et si bien que les API sont bien plus utilisées que les sites web : les API de Twitter reçoivent bien plus de visites que le site web de Twitter, explique Dion Hinchcliffe. L’écosystème de Twitter c’est désormais plus de 10 000 applications tierces (qui utilisent les API de Twitter), et si Twitter fait 20 millions de visiteurs uniques, 40 millions de personnes y accèdent via des applications estime TechCrunch.
Autre difficulté, pour les programmeurs et les sites web qui utilisent ces interfaces : ils dépendent complètement de leurs évolutions. Récemment, Google annonçait faire le ménage dans ses API, expliquant que certaines allaient tout simplement être abandonnées, comme l’API permettant d’utiliser le service Google Translate. Derrière cette décision, ce sont des dizaines de services qui doivent repenser leur offre pour trouver une solution alternative ou fermer à leur tour.
L’internet des API, le web des applications
Les interfaces de programmations et les applications, qui sont leur corollaire, nous font entrer dans un nouveau web ou plutôt une nouvelle étape de l’informatique. Avec d’un côté l’internet des API et de l’autre le web des applications. D’un côté, les échanges d’information entre services qui structurent le réseau, mais demeurent inaccessibles au commun des mortels, de l’autre le web des applications, c’est-à -dire de nanoprogrammes qui utilisent les données de ces API pour rendre l’information plus accessible aux gens. C’est en ce sens qu’il faut regarder l’arriver d’applications dans le navigateur comme le propose déjà Google Chrome ou Mozilla. Si les applications s’expliquaient dans l’univers du mobile et du tactile pour répondre aux spécificités d’utilisabilité de ces interfaces, l’arrivée d’applications dans le navigateur promet d’autres apports et notamment de résoudre les problèmes d’incompatibilité des plateformes, supports et langages. Il permet surtout de simplifier les installations : plutôt que de devoir lancer un programme, préciser où il doit s’installer, configurer son accès, il suffit désormais d’activer une application pour qu’elle soit disponible, que ce soit sur votre ordinateur pour les applications de bureau, sur votre mobile ou dans votre navigateur. Pour Oren Michels, PDG de Mashery, une solution de gestion d’interfaces de programmation, les API semblent être des choses très techniques, très geeks, alors que ce n’est rien d’autre qu’un canal de distribution. Realtibits, une start-up qui propose une solution pour créer des Forums, a ainsi lancé son API avant de lancer son site web, rapporte le ReadWriteWeb. Pour Sam Rami d’Apigee, les API sont la chaîne d’approvisionnement du XXIe siècle (tant et si bien que des services mesurent leurs performances en permanence).
Les API ne sont pas spectaculaires. Elles consistent en de simples entrepôts de données communicants, dont la disponibilité doit être sans faille, au risque sinon de briser toute une chaîne d’accessibilité, car elles ne sont pas seulement utilisées sur le site qui les propose : mais sur une infinité de sites qui les utilisent. Facebook a lancé sa première API en 2006, avant de créer en 2007, une plateforme dédiée aux développeurs. Dans les premiers temps, celle-ci s’est surtout concentrée à fournir le matériel pour construire des applications à l’intérieur de Facebook. Désormais, la vitrine pour les développeurs de Facebook, explique Daniel Luxembourg de Programmable Web, fait uniquement la promotion de mesures techniques permettant d’utiliser Facebook au-delà de Facebook et ce, notamment depuis le lancement en avril 2010 du nouveau graphe Facebook et de l’Open Graph Protocol. Autant d’évolution qui ont permis à Facebook de devenir le troisième service le plus populaire en terme d’utilisation sous forme de mashup (voir le classement), rapporte Programmable Web.

Image : les API les plus utilisées par type sur ces 14 derniers jours, via Programmable web.
Comme l’explique Dion Hinchcliffe dans un récent billet : l’intégration est devenue la vertu à cultiver. “Il est de moins en moins fréquent de voir de nouvelles applications Web apparaitre sans une bonne API qui lui corresponde, car les start-ups ont appris depuis longtemps que si elles ont quelque chose de bien à offrir, l’essentiel de son utilisation viendra des API et non pas de l’expérience utilisateur.†Désormais, les sites ne sont qu’une modalité d’accès. L’essentiel de celui-ci se fait d’une manière distante. “Quand vous commencer à utiliser des API, vous réalisez que ce que vous considériez jusqu’à présent comme le web (les sites web) n’est qu’une manière de voir l’information contenue dans le webâ€, explique Christian Heilmann dans une très claire présentation des enjeux du web de données. Le succès de Facebook ne tient pas tant au succès d’audience du site : de plus en plus il est lié au succès de ses API, à la façon dont d’autres sites exploitent Facebook Connect ou intègrent le Graphe de Facebook dans d’autres services. C’est en cela que Facebook, et la plupart des services majeurs du web 2.0, deviennent chaque jour un peu plus incontournables : leur écosystème ne cessant de s’étendre.
“Au cours de ces dernières années, nous avons vu les API des entreprises devenir plus simples, plus web, plus faciles d’intégration tout en réduisant les coûts d’accèsâ€, explique encore Dion Hinchcliffe. Tant et si bien que leur succès ouvre de nouvelles perspectives d’intégrations des solutions complexes utilisées en entreprise, estime le consultant. Le succès des API des services web devrait inspirer les services professionnels, invités à délivrer désormais leurs données et faciliter leurs intégrations par d’autres sociétés via des interfaces de programmation.
Il n’y a pas de web sans API
Les API sont la clef du web social et du web des données. C’est par elles que transitent les données. C’est par leur croisement que se construisent de nouveaux services et de nouvelles connaissances. Si les données sont les entrepôts d’information, nul n’y accède sans clef, et cette clef, ce sont les API.
Mais c’est là un web dans lequel l’utilisateur n’a qu’une place congrue. Les enjeux sont ailleurs, comme le montrait la récente bataille entre Facebook et Google permettant de croiser les contacts des utilisateurs :
“Dorénavant, les services Web ne pourront utiliser l’interface de programmation (API) qui gère les contacts de Gmail que s’ils “autorisent en contrepartie l’exportation des mêmes informations de contacts de manière simpleâ€.
De nombreux services utilisent l’API de Gmail pour faciliter l’inscription de nouveaux utilisateurs : lorsque l’utilisateur rentre son adresse, le service peut très facilement accéder à son carnet de contact, et donc lui signaler quels sont ses correspondants qui sont déjà inscrits sur le service, ou lui proposer de leur envoyer une invitation. Facebook, notamment, utilise cette API pour proposer aux nouveaux inscrits de retrouver et d’ajouter comme “amis†les correspondants Gmail.
Or Facebook se refuse à proposer la même option aux services tiers. Un nouvel inscrit sur Gmail ne peut pas rentrer son identifiant Facebook pour ajouter automatiquement à son carnet d’adresses ses “amis†du réseau social.â€
La guerre des stratégies autour des API (à savoir la façon dont elles sont proposées, ouvertes, payantes à partir d’un certain seuil d’utilisation, gratuites, réciproques…) est en train de façonner l’internet et tout ce qui en dépend. Pour la plupart des sociétés de l’internet, être accessible via une ou plusieurs API est essentiel pour le développement de son service. Mais pour certains acteurs, la surutilisation de leurs ressources pose question. Les stratégies s’affinent à mesure et peuvent être très différente d’un service l’autre. Certains acteurs ne vont proposer que des API payantes. D’autres vont proposer des API très ouvertes pour être exploitées par le plus grand nombre. D’autres au contraire, semblent vouloir de plus en plus distinguer qui peut accéder ou non à ses API…
Désormais, la plupart des grands services web proposent leurs API. Initiés dès 2000 par l’API d’eBay puis par celle d’Amazon, elles se sont depuis multipliées : d’abord par celles des grands acteurs du web 2.0 permettant l’explosion des Mashups, puis par le développement des API des sites sociaux depuis 2006, comme l’explique très bien Clément Vouillon. Désormais, non seulement tous les sites sociaux proposent une API – comme Linked-in -, mais le phénomène touche désormais des services plus petits, des start-ups moins connues, qui misent sur le développement d’interfaces de programmation pour assurer leur développement.
L’asymétrie des échanges de données
Si via ces API, la circulation des données semble s’ouvrir, les développeurs sont les otages consentants du moindre changement dans les conditions d’utilisations, comme l’explique Clément Vouillon. Mais surtout, dans cet univers, l’utilisateur et ses données semblent être le plus petit dénominateur commun. On a l’impression que s’oppose un monde d’API plutôt ouvertes, où les systèmes discutent entre eux, à un monde d’applications relativement fermées qui jouent des données des utilisateurs sans que ceux-ci en comprennent la portée. Certes, ils en bénéficient aussi. Mais peut-on vraiment bénéficier de choses qu’on ne maîtrise pas, qu’on ne comprend pas ?
En fait, ce n’est pas tant le fait qu’on ne maîtrise pas ou qu’on ne comprend pas les API qui posent problème. C’est plutôt le fait qu’elles utilisent nos données sans que nous nous en rendions vraiment compte. Et surtout qu’elles utilisent nos données de manière asymétrique : c’est-à -dire qu’elles n’utilisent pas nécessairement les mêmes que celles auxquelles nous pensons leur donner accès. Autoriser un service à utiliser nos données sur Facebook, peut l’autoriser à aller chercher dans tout notre historique, faisant apparaître des choses de nous que nous-mêmes avions oubliées.
Le problème des API ne repose pas tant dans la circulation des données que dans leur asymétrie. Comme le disait Kevin Kelly récemment : “Nous ne voulons pas moins de données, nous voulons une plus grande symétrie, tirer plus davantage que ce que l’autre partie sait de nousâ€. Et force est de constater que ce n’est pas ce que proposent les API.
L’article original : http://www.internetactu.net/2011/06/21/comprendre-facebook-33-linternet-des-api-le-web-des-applications/
En complément de cet article : Interview de Karl Dubost responsable des relations avec les développeurs chez Opera, Johann Daigremont à la tête du département des communications sociales aux Bell Labs d’Alcatel-Lucent, et Alexandre Assouad, concepteur de projets chez FaberNovel.
Comprendre les interfaces de programmation